
この記事は 4 分で読めます
マーケティングにおけるクラスター分析とは?考え方の基本を概説

統計学やマーケティングの分野において、「クラスター分析」という言葉を聞いたことはありますか?
今回は、マーケティングにおけるクラスター分析とはなにか、どのような考え方を元に行われるのかを概説します。
目次
クラスター分析とは様々な情報が混在しているデータを分類し、整理する手法
クラスター分析とは、混在しているデータを、近いもの同士からなる集団(クラスター)に分けて分析する手法のことです。
一見乱雑に見えるデータも、近いもの同士の集団に分けることによって、今まででは分かりづらかった情報が見えるようになります。
クラスター分析を行う流れ・具体例
クラスター分析は、小売店舗における顧客の特性の把握や、商品を選ぶ傾向の分析などに用いられます。そのほかにも、アンケート結果の集計、地域柄の類似度などの分析にも活用できます。
例えば、とある飲食店が来店客に対して、店舗の満足度に関するアンケート調査を実施したとします。その調査のうち、3人に関する回答を見てみましょう。
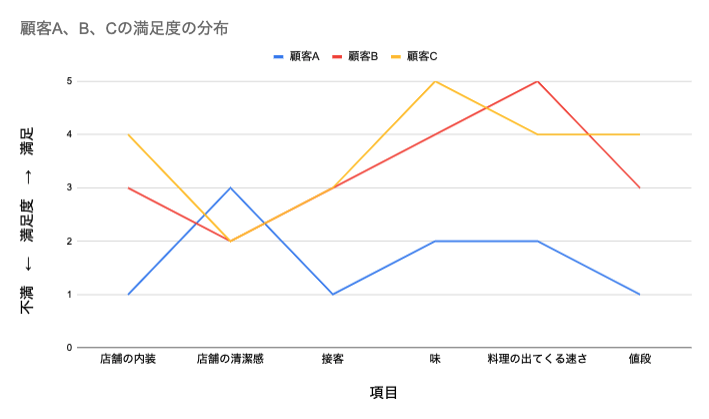
グラフから、おそらく顧客Bと顧客Cは似た顧客である、つまり同じ集団に分類されると判断できます。
マーケティングにおけるクラスター分析の目的は、このように顧客同士がどれだけ互いに類似しているか、あるいは異なっているかを把握することです。
今回の場合は顧客の数が3人であったため、顧客全体は、顧客Bと顧客Cのグループと、顧客Aのグループの2つのグループに分類されることが明らかです。
このように、クラスター分析を行うことによって、どれだけデータ同士が互いに近いのかが数値や表として出力され、データの分類を楽に行うことが可能になります。
クラスター分析で得られた情報をマーケティングに活用する
クラスター分析を行うことによって、商品や顧客を様々な観点から分類できるようになります。
マーケティングにおいてクラスター分析を導入した場合、以下のようなケースが活用例として考えられます。
- 似た販売傾向を持つ商品同士をセットにして販売する
- 顧客と商品の両方を集団にわけ、各顧客の集団にあったグループの商品を提案する
- それぞれの顧客のグループに対してカスタマイズされたPRを行う
- 顧客がインターネット検索したワードを分類し、ニーズを明確にする
このように、商品・顧客を分類することで特性に応じた最適な販売戦略を展開したり、ニーズを明確にしたりすることが可能になります。
階層クラスター分析:樹形図を作り、データを可視化する
クラスター分析の手法の1つに、階層クラスター分析という手法があります。
この手法では最終的に樹形図を描き、どのデータ同士が似ているのか、似ていないのかを明らかにします。
階層クラスター分析および出力される樹形図の例
コンビニの飲み物の販売傾向について、「売上個数」と「価格」の情報を元に商品ごとの分析を行うケースを例として、階層クラスター分析の基本的な考え方を概説します。
- それぞれの飲料の月ごとの売上個数と価格を下図のようなグラフにまとめる
- その中で、グラフ上でお互いに近い点から順番に、以下の赤線のように集団としてまとめる

- 上のグラフでまとめたグループを元に、以下のような樹形図を作成する。
この時、点を囲っている赤い円が小さいものから順番に、樹形図の低い位置で合流させる。

樹形図で「より低い位置で合流している物」=「より類似している物」であるため、今回の例だと、麦茶と烏龍茶が商品の特性として最も類似していることがわかります。
また、同じ高さで合流しているものは同じ程度の類似度を持っています。
階層クラスター分析のメリット・デメリット
階層クラスター分析を行うことの最大のメリットは、結果が樹形図として出るため、どのデータ同士が類似しているのかが視覚的にわかることです。
扱うデータの数が多くなっても、樹形図を下から順番に見ていくことによって類似度の大小を比較することが可能です。
また、分析を行った後に、全体をいくつの集団に分けるかを変更することが可能です。
上記の例だと、青い点線の高さで見た場合は4つの集団に、オレンジの線の高さで見た場合は3つの集団に飲み物を分けられます。

デメリットは、大量のデータを扱う際に樹形図が複雑になってしまうほか、計算自体も複雑になるため統計ソフトを用いる必要があることです。
非階層クラスター分析:事前に決めた数のグループにデータを分ける
非階層クラスター分析は基本的に自動で計算が行われ、似ているもの同士が同じ集団に分類、似ていないものは違いを目立たせるように処理されます。
非階層クラスター分析および結果から推定できる情報の例
非階層クラスター分析はk-平均法に代表されるようなアルゴリズムを用いて行われます。
この手法では、予めデータを分類する集団の数を決めておき、アルゴリズムが指定した数の集団にデータを分類します。
例えば、小売店舗において、顧客の「過去の来店回数」と「1回の来店あたりの購入金額」のデータを入力し、3つの集団に分けることを指定してアルゴリズムにかけると、以下のような結果が得られます。

樹形図を出力する階層クラスター分析に対して、非階層クラスター分析のアルゴリズムでは点を指定された数の集団に分けること以外は行いません。
今回の場合では、
- 来店回数が少なく、1回あたりの購入金額も少ない集団
- 来店回数は多いが、1回あたりの購入金額が少ない集団
- 来店回数・1回あたりの購入金額の両方が多い集団
の3つの集団に分かれること以外は非階層クラスター分析ではわからないため、結果の解釈は自分で行う必要があります。
非階層クラスター分析のメリット・デメリット
非階層クラスター分析ではアルゴリズムが計算を行うため、階層クラスター分析より多くの情報を扱うことが可能です。そのため、ビッグデータなどを扱う際は非階層クラスター分析のほうが適しています。
その一方で、非階層クラスター分析では事前にいくつの集団にデータを分類するかを決めなければいけません。そのため、いざ分類してみてもデータの傾向がわかりづらく、分類する数を変えて再び分析を行わなければならない可能性があります。
また、アルゴリズムの都合上、同じデータを分析しても結果が多少異なることがあります。
いかがでしょうか?
今回はクラスター分析について、数学的な話には触れず、概説してみました。
記事で取り上げた考え方やメリット、デメリットを踏まえて、クラスター分析を導入してみましょう!



改善の打ち手が見つかる営業の分析手法8選
無料でダウンロードするために
以下のフォーム項目にご入力くださいませ。



